
The basic model in distribution testing is that we receive independent and identically distributed samples of an unknown (discrete) distribution, and aim to decide whether it possesses a certain property or not. Here we are interested in how many samples are required to reliably answer fundamental questions about the relationship between distributions over multiple variables by testing whether there are (conditional) correlations between them.
A natural way to formalize this in an information-theoretic way is to ask whether two variables of a bipartite distribution are independent or have a mutual information above some threshold . The mutual information is zero exactly when , i.e., when there are no correlations between and . If the system has at least three variables, we may also ask whether these are conditionally independent, or have conditional mutual information . Conditional independence intuitively means that and may be correlated, but their correlations are due to , such that observed correlations between and can be explained without requiring ‘interactions’ between and . It is not difficult to show that this is the case if and only if (on the support of ). Recall that .
A related problem has previously been studied by Canonne, Diakonikolas, Kane, and Stewart (STOC 2018), where the farness guarantee was expressed using the so-called total variation distance instead of the conditional mutual information. This algorithm might be applied to our problem of (conditional) mutual information testing, however it is not sample optimal for this task.
Our algorithm aims to reduce the problem to instances of equivalence testing, that is, testing whether two unknown distributions are equal or not. We first simulate samples from and compare it to . The testing itself uses a reduction to -distance, pioneered by Diakonikolas and Kane (FOCS 2016), in which the domain is partitioned into subsets , based on the weight of . This allows us to tightly link guarantees in the -distance to the conditional mutual information. The subsets are then tested separately. Our partitioning is tailored to also take the specific structure of into account, to be even more efficient than general equivalence testing.
However, a major obstacle is sampling from : while it turns out that for ‘large’ , this is relatively straightforward, we are not able to perfectly sample from for where is ‘small’. Intuitively, this would require the ability to sample from . Instead, we try to approximately simulate in this regime, but the resulting samples are both correlated and biased, which leads to different regimes. Our sample complexity and the sample complexity by Canonne et al. are shown below, up to polylogarithmic factors. The sizes of the subsystems are given by , , and , respectively. The parameter denotes the farness guarantee in conditional mutual information, and the corresponding guarantee in the total variation distance problem.
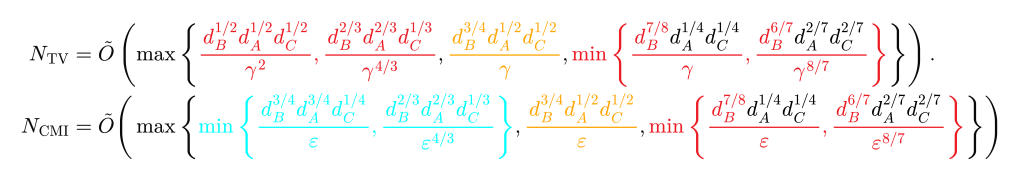
Existing lower bounds on the sample complexity are marked in color (red: derived by Canonne et al., blue: by Seyfried et al., yellow: by Canonne et al. for the special case where , ). These bounds already proved that the observed structure with various case distinctions is ‘right’ – the five different regimes and nested case distinctions are necessary. However, the exact form of certain terms was not clear. This left the door open for a possible improvement, in particular in the regime where we were not able to reduce the problem to equivalence testing in a direct manner.
In our follow-up work, we showed that the sample complexities derived by Canonne et al. for conditional independence testing and Seyfried et al. for conditional mutual information testing are indeed optimal, up to logarithmic factors. Our proof is based on generalizing the constructions by Canonne et al., which did not fully resolve all regimes.
For further details, please see Seyfried, Sen, and Tomamichel (COLT 2025) for our algorithm to test conditional mutual information, and Seyfried, Mishra, Sen, and Tomamichel (COLT 2026) for the aforementioned lower bounds.